- Have any questions?
- +91 99908 16780
- info@ai-cbse.com
What is a Classification AI Model

Data, Algorithm and Model
February 3, 2017
Classification AI Model
What is a Classification AI Model?
In the realm of artificial intelligence and machine learning, a classification model is designed to categorize data into predefined classes or categories. Unlike regression, which predicts continuous outcomes (like predicting the price of a house), classification focuses on assigning data points to specific categories based on their features.
For example:
- Email Classification: Determining whether an email is spam or not.
- Medical Diagnosis: Classifying whether a patient has a particular disease based on their symptoms and test results.
- Image Recognition: Identifying whether an image contains a cat, dog, or another object.
How Do Classification Models Work?
Classification models work by analyzing input data and assigning it to one of several categories based on learned patterns. Here’s a step-by-step overview:
- Data Collection: Gather and prepare a dataset that includes examples of each category you want to classify. For instance, if you’re building a model to classify emails as spam or not spam, you need a dataset of emails labeled accordingly.
- Feature Extraction: Identify and extract relevant features from the data. In email classification, features might include keywords, the sender’s address, or the email’s length.
- Model Training: Use a portion of your dataset (training data) to teach the model how to distinguish between categories. The model learns by adjusting its parameters to minimize errors in predictions.
- Model Testing: Evaluate the model’s performance on a separate portion of the dataset (test data) to ensure it generalizes well to new, unseen data.
- Prediction: Use the trained model to classify new data points. For instance, you can input a new email into your spam filter and the model will predict whether it’s spam or not.
Common Classification Algorithms
Several algorithms are commonly used for classification tasks, each with its strengths and suitable applications:
1. Logistic Regression
Despite its name, logistic regression is a classification algorithm used for binary classification tasks (two categories). It estimates the probability that a data point belongs to a particular class.
Example: Predicting whether a student will pass or fail based on hours studied.
2. Decision Trees
Decision trees create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features. It resembles a flowchart where each node represents a feature, and each branch represents a decision outcome.
Example: Classifying whether a customer will buy a product based on their age and income.
3. Random Forest
Random forest is an ensemble method that combines multiple decision trees to improve classification accuracy. Each tree in the forest votes on the classification, and the majority vote determines the final output.
Example: More robustly classifying emails as spam or not by averaging the decisions from multiple trees.
4. Support Vector Machines (SVM)
SVMs find the hyperplane that best separates the data into classes. They work well for both linear and non-linear classification tasks by using kernel functions.
Example: Classifying images as containing either a cat or a dog.
5. K-Nearest Neighbors (KNN)
KNN classifies a data point based on how its neighbors are classified. It looks at the ‘k’ nearest neighbors and assigns the most common class among them.
Example: Classifying a new product based on the similarity to existing products.
Evaluating Classification Models
To determine how well your classification model is performing, you need to evaluate its accuracy and other metrics. Common evaluation metrics include:
- Accuracy: The ratio of correctly predicted instances to the total instances.
- Precision: The ratio of true positive predictions to the total predicted positives.
- Recall: The ratio of true positive predictions to the total actual positives.
- F1 Score: The harmonic mean of precision and recall, useful for balancing both metrics.
Confusion Matrix: A table used to evaluate the performance of a classification model by showing true positives, false positives, true negatives, and false negatives.
Real-World Applications
Classification models are used in various domains:
- Healthcare: Diagnosing diseases based on patient data.
- Finance: Fraud detection by classifying transactions as fraudulent or legitimate.
- E-commerce: Personalized recommendations based on user preferences and behavior.
Challenges in Classification
- Imbalanced Data: When one class is much more frequent than others, leading to biased models.
- Overfitting: When a model learns the training data too well and performs poorly on new data.
- Feature Selection: Identifying the most relevant features to improve model performance.
Conclusion
Classification AI models are powerful tools that help us categorize and make decisions based on data. From sorting emails to diagnosing diseases and beyond, understanding these models equips you with the knowledge to tackle various problems and harness the potential of AI in meaningful ways.
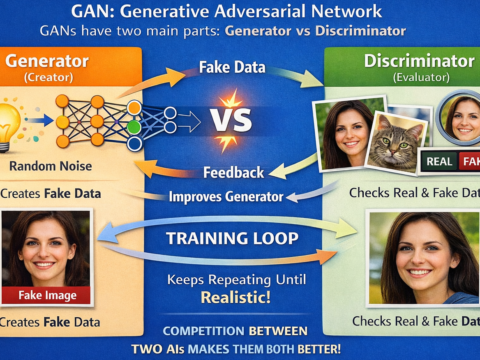
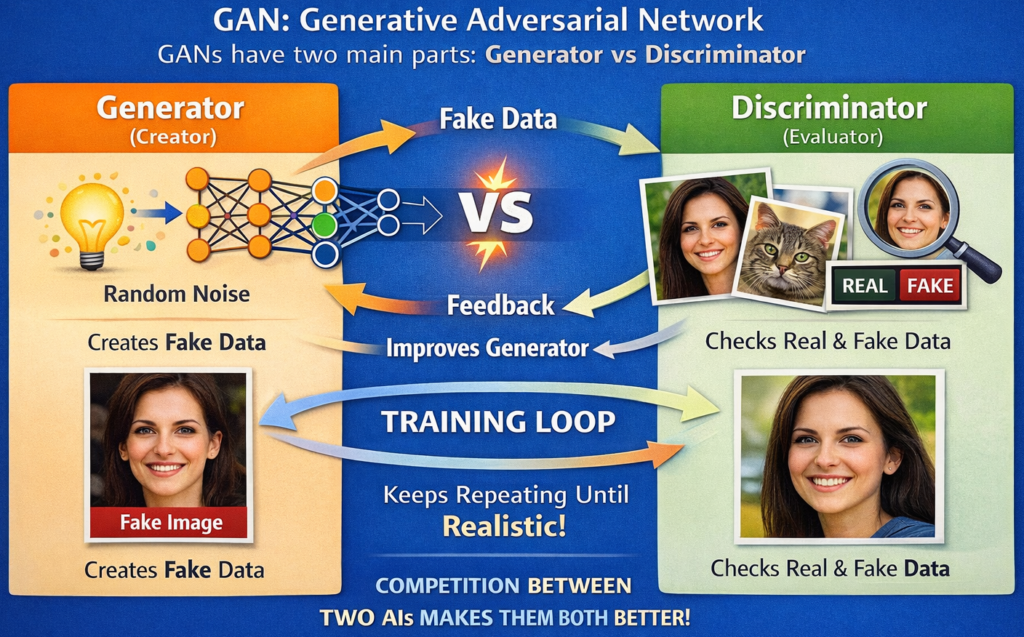{kind=link}
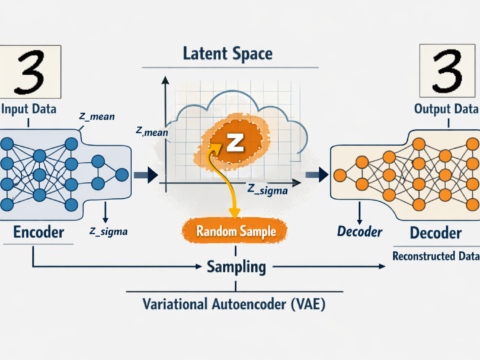
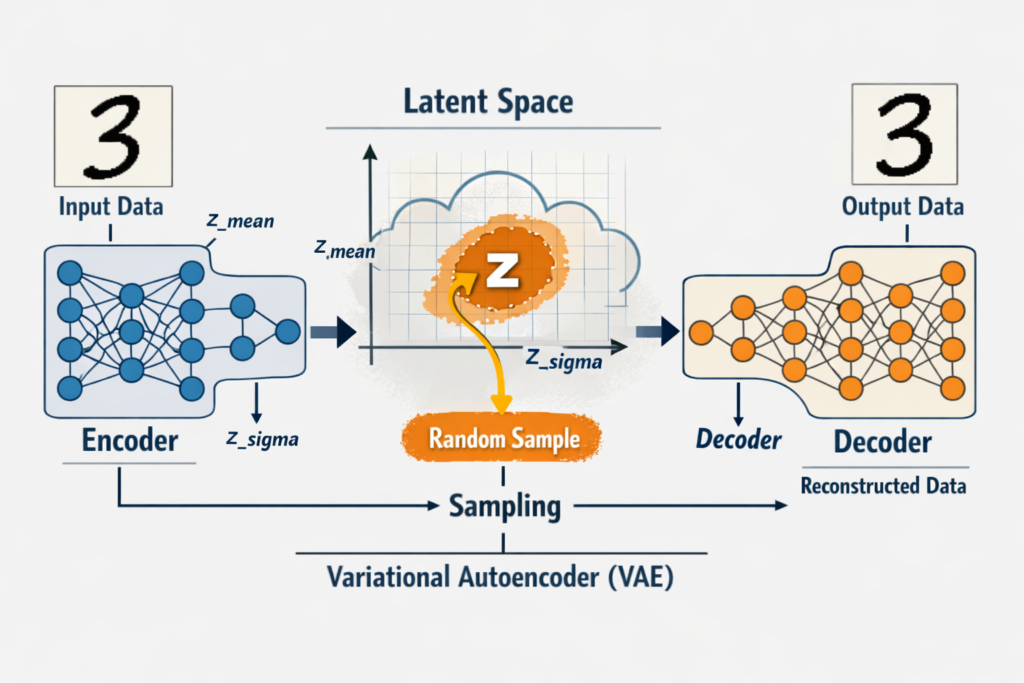{kind=link}